
# print () 函数与变量
# 难点
1.print () 函数以及引号的使用
2. 换行的两种简便方法
3. 区分赋值与等于
# 重要内容
# 一、最基本的一条代码
\1. print () 函数 print () 函数由两部分构成:
指令:print;
指令的执行对象:在 print 后面的括号里的内容
\2. 引号的用法
单引号和双引号都可以使用,但需要匹配,并且配合使用可以区分开原文和 print () 函数的结构。例如,print (“Let’s go”),双引号的作用是函数结构,单引号是英文语法。
不用引号时,括号内必须是数字或者数字运算,这是计算机可以理解的内容。例如:print (1+1),最后输出是 2。
注意:python 中所有的符号都是英文状态下的,并且会区分大小写。
# 二、换行
重复使用 print () 函数,将不同行的语句放在不同的函数中输出。(事倍功半)
使用三引号:用三引号将需要分行的内容括起来,并且在引号内使用回车进行段落排版。例如:
print('''我愿意留在汤婆婆的澡堂里工作两年, | |
第一年在锅炉房和锅炉爷爷一起烧锅炉水, | |
第二年在澡堂给客人搓背, | |
如果我违背工作内容的话, | |
将在这个世界变成一头猪。''') |
- 使用 \n,此时是不允许回车换行的!例如:
print('我愿意留在汤婆婆的澡堂里工作两年,\n第一年在锅炉房和锅炉爷爷一起烧锅炉水,\n第二年在澡堂给客人搓背,\n如果我违背工作内容的话,\n将在这个世界变成一头猪。') |
# 三、转义字符
对于可作为结构性符号的,例如单引号,感叹号,若想直接使用,可在符号前加一个反斜线 \。则对于之前的例子:print (“Let’s go”),也可以写作 print (‘Let\’s go’), 中间的单引号由于使用了反斜线,所以作为整条语句的内容而不是 print () 函数的结构。
# 四、变量与赋值
变量是我们自己创建的,命名要求:
只能是一个词
只能包含字母、数字、下划线(下划线可以用于连接多词)
不能以数字开头
尽量描述包含的数据内容(抽象概括存储的内容)
代码中的 =(等号)是用于赋值而逻辑上的等于要使用两个等号,即 1+1==2。
变量的特点:保存的数据是可以随意变化的,储存的值永远都是最新的那个。例如:
name='魔法少女千酱' | |
name='夏目千千' | |
name='千寻' | |
print(name) |
这段代码输出是结果是‘千寻’
# 数据类型与转换
# 难点
1. 区分字符串下的数字与整数、浮点数下的数字
2. 使用【+】进行数据拼接时,连接的数据类型必须为同数据类型
3. 使用函数进行数据类型的转换时,int () 与 float () 函数括号内的数据必须为纯数字型文本
# 重要内容
# 一、常见的三种数据类型
1、字符串
特点:被引号括起来的文本。(注意引号要使用英文状态下的单引号或者双引号、三引号)例:
slogan = '命运!不配做我的对手!' | |
attack = "308" | |
gold = "48g" | |
blood = '''+101''' | |
achieve = "First Blood!" |
先将内容以字符串形式赋值给变量,最后使用 print () 函数输出变量即可。
2、整数
整数英文为 integer,简写做 int。是正整数、负整数和零的统称,是没有小数点的数字。
特点:无需配合引号使用,可进行计算。如:108(整数)‘108’(字符串)‘6 小灵童’(字符串)但若存在文字类数据,则必须使用引号,将其变为字符串类型。例:
print(6小灵童) | |
print(6skr) | |
#打印数据 | |
SyntaxError: invalid syntax | |
#终端显示结果:报错:无效语法 |
具体的计算符号:(优先级与日常算数一致)

3、浮点数
相对于整数而言,浮点数就是带小数点的数字。英文名是 float,与整数 int () 和字符串 str () 不同,浮点数没有简写。
# 二、查询数据类型 ——type () 函数
作用:查询数据类型
例:print (type (' 查询内容 '))
achieve = 'Penta Kill' | |
print(type(achieve)) | |
#结果显示:<class'str'> |
# 三、数据拼接
利用数据拼接符号【+】,将需要拼接的变量连在一起。注意:变量内的数据类型必须为字符串型才可进行拼接!如:
hero = '亚瑟' | |
enemy = '敌方' | |
action = '团灭' | |
gain = '获得' | |
achieve = 'ACE称号' | |
#结果显示为 | |
#亚瑟团灭敌方获得 ACE 称号 | |
print(hero+action+enemy+gain+achieve) | |
hero = '亚瑟' | |
enemy = '敌方' | |
action = '秒杀' | |
gain = '获得' | |
number = 5 | |
achieve = 'Penta Kill' | |
print(hero+action+number+enemy+gain+achieve) | |
#结果显示报错:TypeError:can only concatenate str (not "int") to str | |
#类型错误:只能将字符串与字符串拼 |
# 四、数据类型转换
1、转换为字符串类型
str () 函数能将数据转换成其字符串类型。只要将所需数据放到括号里,这个数据就能成为字符串类型。
用引号将数据括起来也能达到同样结果。
例如:
hero = '亚瑟' | |
enemy = '敌方' | |
action = '秒杀' | |
gain = '获得' | |
number = 5 | |
achieve = 'Penta Kill' | |
print(hero+action+str(number)+enemy+gain+achieve) | |
print(hero+action+'5'+enemy+gain+achieve) | |
#使用 str () 函数将变量 number 里的数字 5 变成了字符串 5。 |
2、转换为整数
int () 函数的使用,与 str () 类似。注意一点:只有符合整数规范的字符串类数据,才能被 int () 强制转换。
print(int('3.8')) | |
#运行后显示结果:ValueError:invalid literal for int () with base 10: '3.8' |
小数型字符串会直接报错,而浮点数会被强制转换:
print(int(3.8)) | |
#运行后结果显示: |
也就是说,对于浮点数,int () 会保留其整数部分。注意:不是四舍五入!
3、转换为浮点数
float () 函数的使用与 int ()、str () 类似。如果括号里面的数据是字符串类型,那这个数据一定得是数字形式。
# 条件判断与条件嵌套
# 难点
1. 逻辑判断应使用逻辑符号等于【==】
2. 条件语句后一定要记得接冒号【:】,注意观察冒号之后的语句是否缩进以及同级别的语句是否在格式上处于并列状态。
3. 在执行变量的判断之前,要注意变量是否已经被赋值
# 重要内容
# 一、条件判断
即中文逻辑语句 “如果... 就...”。在进行判断之前,一定要先对变量进行赋值!条件判断就是针对不同的可能性,进行不同操作。赋值情况的前提不满足 if 的条件时,自动跳过,执行下一行命令。
其次,每一个判断语句之后要使用冒号【:】,表示接下来的内容是只有满足条件才运行的。若不是条件下的语句,要记得删除缩进。
1、单向判断
要是 if 之后的条件不满足,就跳过 if 语句进行下一命令。格式:
if xxx (判断的条件):
如果满足上述条件,就执行的操作语句
2、双相判断
要是 if 之后的条件不满足,就执行 else 里的。if 与 else 平级(缩进一致,在 else 前必须有一个平级的前提)。每一个条件不能有重合部分,是互斥的,格式:
if xxx (判断的条件):
如果满足上述条件,就执行的操作语句
else:
如果不满足 if 之后的语句,就执行的操作语句
weight=101 | |
#要先为酱酱的体重赋值,酱酱的体重是 101 斤 | |
if weight>100: | |
#如果体重超过 100 斤的条件下,就……(条件后需加冒号) | |
print('不吃了') | |
#就打印结果:不吃了!(注意检查是否自动缩进) | |
else: | |
#如果体重没有超过 100 斤的条件,就……(else 条件前无缩进,条件后需加冒号) | |
print('放心吃吧') | |
#就打印:放心吃吧 (注意检查是否自动缩进) |
3、多向判断
if、elif 和 else 平级。可以存在多个 elif,数量根据整体能分成的所需选项数来定。注意:每一个条件不能有重合部分,是互斥的,即 x<10 与 9<x<15,这样的两个条件是不可行的。如果不满足 if 的条件,就判断是否满足 elif 下的条件,若所有 elif 的条件都不满足,就执行 else 下的语句。并且 elif 之后可以不接 else,格式:
if xxx (判断的条件):
如果满足上述条件,执行的操作语句
elif xxx (与前一个 if 互斥的另一个条件):
如果满足 elif 后的条件,就需要执行的语句
else:
若 if、elif 后面的条件都不满足,则会执行的语句
stonenumber=1 | |
#一定要先为宝石数量赋值 | |
if stonenumber>=6: #注意冒号 | |
#条件:如果你拥有的宝石数量大于等于 6 个 | |
print('你拥有了毁灭宇宙的力量') #注意缩进 | |
elif 3<stonenumber<=5: | |
#条件:如果宝石数量在 4 至 5 个 | |
print('红女巫需要亲手毁掉幻视额头上的心灵宝石') | |
else: | |
#条件:当赋值不满足 if 和 elif 条件时,执行 else 下的命令,即宝石数量在 3 个以下 | |
print('需要惊奇队长逆转未来') |
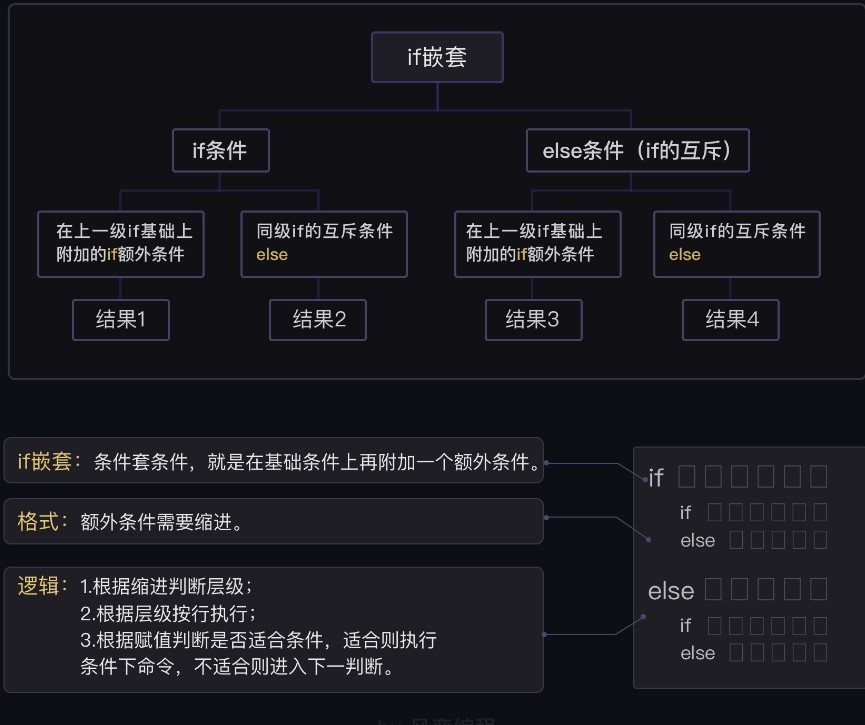
# 二、if 嵌套
在基础条件满足的情况下,再在基础条件底下增加额外的条件判断。在编写 if 嵌套语句时,同样的,可以按照框架,从大到小,依次往不同的大条件中补充额外条件。
historyscore=26 | |
if historyscore>=60: | |
print('你已经及格') | |
if historyscore>=80: | |
print('你很优秀') | |
else: | |
print('你只是一般般') | |
else: | |
print('不及格') | |
if historyscore<30: | |
print('学渣') | |
else: | |
print('还能抢救一下') | |
print('程序结束') | |
#结果显示为 : | |
#不及格 | |
#学渣 | |
#程序结束 |
每一个级别下的条件都只能执行一个!(互斥)elif 与 if 类似。
# input () 函数
# 难点
input () 函数括号内的内容会被输出,但需要输入对应数据才能继续执行之后代码
input () 函数的结果必须赋值给变量,且数据类型为字符串型
# 重要内容
# input () 函数
1、定义
input () 函数是输入函数,与 print () 函数类似,input () 函数括号里面的内容是会显示出来的,但不同在于我们需要输入对应的内容,回车后才能继续运行。
2、input () 函数赋值
在括号内用引号括起提示语,例:
input('请铲屎官输入宠物的名字:') | |
#运用 input 函数搜集信息 |
输入的内容被储存在计算机内,需要将结果赋值给变量。例:
print('那么,您的选择是什么?"1"接受,还是"2"放弃呢?') | |
choice = input('请输入您的选择:') | |
#变量赋值 | |
if choice == '1': | |
print('霍格沃茨欢迎你的到来') | |
else: | |
print('您可是被梅林选中的孩子,我们不接受这个选项。) |
3、input () 函数的数据类型
对于 input () 函数来说,不管输入的是整数 1234,还是字符串‘我爱摩卡’,input () 函数的输入值(搜集到的回答),永远会被强制性地转换为字符串类型。(Python3 固定规则)所以,不管我们在终端区域输入什么,input () 函数的返回值一定是字符串,将结果赋值给变量后,变量的数据类型也一定是字符串。
4、input () 函数的数据类型转换
使用数据类型转换函数,int (),float () 可以从源头强制转换为对应类型。但是要注意,此时的 input () 函数返回值一定要是纯数字型!例:
money = int(input('你一个月工资多少钱?')) | |
#将输入的工资数(字符串),强制转换为整数 | |
if money >= 10000: | |
#当工资数(整数)大于等于 10000(整数)时 | |
print('土豪我们做朋友吧!') | |
#打印 if 条件下的结果 | |
else: | |
#当工资数(整数)小于等于 10000(整数)时 | |
print('我负责赚钱养家,你负责貌美如花~') | |
#打印 else 条件下 |
注:输入值会运用到计算时,千万记得用 int () 转换!
# 列表和字典 - 收纳的艺术
# 难点
列表与字典增删改查的异同
正确使用切片,深刻理解切片时冒号左右数字的意义
# 重要内容
# 一、列表
- 代码格式
数据存储在中括号 [] 里,用逗号隔开并使用等号赋值给列表。中括号里面的每一个数据叫作 “元素”。
列表中的元素是有自己明确的 “位置” 的,元素相同,在列表中排列顺序不同,就是两个不同的列表。
列表中字符串、整数、浮点数都可以存储。
list = ['小明',17,5.2] |
- 提取元素
1)偏移量:元素在列表中的编号。
偏移量是从 0 开始的;
列表名后加带偏移量的中括号,就能取到相应位置的元素。
结果是一个元素
2)切片:用冒号来截取列表元素的操作。
冒号左边空(或者为 0), :m,表示从头取 m 个元素;
右边空(或者为 0),n: ,跳过前 n 个元素把剩下的取完;
冒号左右都有数字时,n:m,表示跳过前 n 个元素,取到第 m 个。(取出前 m 个元素中除了前 n 个后剩下的那些)
切片截取了列表的一部分,所以得到的结果仍然是一个列表。(即使只有一个元素,也是在列表里的,要与用偏移量取单个元素的方法区别开)
students = ['小明','小红','小刚'] | |
print(students[2]) | |
#使用偏移量提取单一元素,结果显示: | |
#小刚 | |
print(students[2:]) | |
#使用切片,即使结果仍然只有一个元素,但显示为列表: | |
#[' 小刚 '] |
3)特别地,a,b,c=students,也可以提取出列表中的元素,变量分别用逗号隔开,且变量的数量与列表元素个数一致,最终列表元素会分别赋值给变量,例如:
appetizer = ['话梅花生','拍黄瓜','凉拌三丝'] | |
a,b,c=appetizer | |
print(a) | |
print(b) | |
print(c) | |
print(a,b,c) | |
#结果显示为 | |
#话梅花生 | |
#拍黄瓜 | |
#凉拌三丝 | |
#话梅花生 拍黄瓜 凉拌三丝 |
- 增加 / 删除元素
1)增加元素
列表名.append ()。注意这里是 **.** 不是空格!
append 后的括号里只能接受一个参数,结果是让列表末尾新增一个元素。列表长度可变,理论容量无限,所以支持任意的嵌套。
list3 = [1,2] | |
list3.append(3) | |
print(list3) | |
#添加‘3’这个元素 | |
#结果显示: | |
#[1,2,3] | |
list3.append(4,5) | |
list3.append([4,5]) | |
print(list3) | |
#添加‘[4,5]’这个列表,也就是 append () 的参数为一个列表,也是一个参数,所以不会报错 | |
#结果显示: | |
#[1,2,3,[4,5]] |
但是 append (4,5) 会报错,因为给了两个元素(没有作为一个整体,所以算两个参数)。注意!!千万不能:a=student.append (3),这样 a 里只有 none。
2)删除元素
del 列表名 [元素的索引] 。注意这里是空格不是。了!
与 append () 函数类似,能删除单个元素、多个元素(切片)、整个列表。
3)修改元素
使用偏移量修改对应位置的元素。
list1 = ['小明','小红','小刚','小美'] | |
list1[1] = '小蓝' | |
print(list1) | |
#结果显示 | |
#[' 小明 ',' 小蓝 ',' 小刚 ',' 小美 '] |
# 二、字典
字典所存储的两种数据若存在一一对应的情况,用字典储存会更加方便。唯一的键和对应的值形成的整体,我们就叫做【键值对】。键具备唯一性,而值可重复。
- 代码格式
字典外层是大括号 {},用等号赋值;
列表中的元素是自成一体的,而字典的元素是由键值对构成的,用英文冒号连接。有多少个键值对就有多少个元素。如 ' 小明 ':95,其中我们把 ' 小明 ' 叫键(key),95 叫值 (value)。
键值对间用逗号隔开
字典中数据是随机排列的,调动顺序也不影响。所以列表有序,要用偏移量定位;字典无序,便通过唯一的键来定位。
(注:len () 函数用于获取数据长度)
students = ['小明','小红','小刚'] | |
scores = {'小明':95,'小红':90,'小刚':90} | |
print(len(students)) | |
print(len(scores)) | |
#结果显示 | |
#3 | |
#3 | |
#字典的元素个数,数冒号就行了 |
- 提取元素
字典没有偏移量,所以在提取元素时,中括号中应该写键的名称,即字典名 [字典的键]。提取出来的是 key 对应的 value,而不会显示键的数据!
scores = {'小明': 95, '小红': 90, '小刚': 90} | |
print(scores['小明']) | |
#结果显示 | |
#95 |
- 增加 / 删除元素、
1)新增元素
字典名 [键] = 值。每次只能新增一个键值对。scores [' 小刚 ',' 小美 ']=92,85,这样是不对的,最终会输出 (' 小刚 ',' 小美 ':(92,85)) 作为一个键值对。
album = {'周杰伦':'七里香'} | |
album['王力宏'] ='心中的日月' | |
album['林俊杰'] = '小酒窝' | |
print(album) | |
print(album['周杰伦']) | |
#结果显示 | |
#{' 周杰伦 ':' 七里香 ',' 王力宏 ':' 心中的日月 ',' 林俊杰 ':' 小酒窝 '} | |
#七里香 |
2)删除元素
del 字典名 [键]
album = {'周杰伦':'七里香','王力宏':'心中的日月'} | |
del album['周杰伦'] | |
print(album) | |
#结果显示 | |
#{' 王力宏 ':' 心中的日月 '} |
3)修改元素
如果不是整个键值对都不需要,只需要改变对应 key 下的 value,修改就可以,不需要 del。
dict1 = {'小明':'男'} | |
dict1['小明'] = '女' | |
print(dict1) | |
#字典没有偏移量,只能通过 key 找到元素位置 |
# 三、列表与字典的嵌套
- 列表与列表
列表中有两个列表元素,1 表示取第二个元素(列表),2 表示取第二个元素中的第三个元素(偏移量为 2)。
student=[['小红','小黄','小橙'],['小绿','小蓝','小紫','小青']] | |
print(student[1][2]) | |
#结果显示为 | |
#小 |
- 字典与字典
字典中存储了两个字典,所以提取数据时只能用 key 值。
scores={'第一组':{'小明':95,'小红':96},'第二组'{'小刚':94',小青':99}} | |
print(scores['第一组']['小红']) | |
#结果显示: | |
#96 |
- 列表与字典
使用偏移量从最外层括号到最内层括号取数。查找 townee 列表中的第六个元素中的第 2 个元素(一定是字典,因为之后用的是键值而不是偏移量)中 key 为 ' 反面角色 ' 的 value。
townee = [ | |
{'海底王国':['小美人鱼''海之王''小美人鱼的祖母''五位姐姐'],'上层世界':['王子','邻国公主']}, | |
'丑小鸭','坚定的锡兵','睡美人','青蛙王子', | |
[{'主角':'小红帽','配角1':'外婆','配角2':'猎人'},{'反面角色':'狼'}] | |
] | |
print(townee[5][1]['反面角色']) |

2021.8.15
END...